16 Серпня, 2018 1 хв

Досвід побудови першої нейронної мережі в юридичній фірмі by Legal Engineer

В лютому 2017 на одному із пленінгів я попросив не давати мені юридичну роботу, поки не допрограмую одну штуку. Потім почав програмувати іншу, за нею ще іншу. Так я став Legal Engineer. А навесні 2018 зробив в Axon Partners внутрішнє демо нашої першої нейронної мережі.
Останнім часом своїм колегам я більше нагадую фанатика-лінгвіста, ніж юриста-кодера. Це через роботу над новим секретним проектом. Є в ньому одна біда, про яку не можу промовчати. Тому і починаю цикл статей про жорсткий лігалтек з natural language processing і neural networks. Го розважимось, legal hackers!
Визначення правильного сенсу багатозначних слів — це класична проблема в комп’ютерній лінгвістиці. Нам треба навчитись робити це якісно. Обраний піддослідний — слово “легалізація”. Для початку буду вживати в цій статті винятково іменник “легалізація”, не зачіпаючи похідні дієслова (“легалізувати”), дієприкметники (“легалізований”) та дієприслівники (“легалізуючи”).
Чому саме “легалізація”? Тому, що в цього слова вимальовується одразу чотири смислові значення, причому аж всі вони мають юридичний контекст! Дивіться самі:
- узаконення [діяння], наприклад: проституції, марихуани, носіння вогнепальної зброї;
- відмивання [доходів], це можуть бути кошти, майно, доходи тощо;
- підтвердження[документа], мається на увазі консульська легалізація;
- засвідчення [підпису], це теж стосується консульської легалізації, але пропоную поки проігнорувати цей чудовий сенс, щоб менше плутатись.
Пропоную перші три сенси зображувати у різних кольорових гамах, це нам допоможе:

Як нас того навчають у школах, сенс багатозначного слова виявляється через його контекст, тобто за допомогою слів, які його оточують і з ним пов’язані. Давайте перевіримо, чи це дійсно так:
- «Отже, легалізація документа необхідна для надання йому юридичної сили на території іншої держави.»
- «Водночас легалізація дозволить секс-працівникам, секс-агентствам і клієнтам використовувати стандартні ринкові механізми для зниження ризиків у плані здоров’я та підвищення якості послуг.»
- «Легалізація “брудних” коштів є одним із факторів, що обумовлює існування “тіньової економіки”…»
Доволі просто, чи не так? В першій ситуації можемо підставити слово “підтвердження”, в другій — “узаконення”, а в третій — “відмивання”, і сенс речення залишиться той самий. Ми, люди, робимо це автоматично. Але насправді наш мозок в цей момент аналізує смислові зв’язки багатозначного слова з іншими словами в процесі читання речення/тексту.
Якщо в процесі читання якогось речення/тексту вперше робити це складно, то спочатку читаємо його до кінця, щоб уловити “загальну суть”, а потім завдяки цьому розуміємо значення слова. Цього навчають у школі. Якщо ж для виявлення сенсу слова “легалізація” необхідно аналізувати сусідні слова, то логічно, що це мають бути якісь конкретні слова, що вказують на потрібний сенс. Їх можна рахувати і потім порівнювати кількість.
Тому спочатку я вирішив створити для кожного сенсу групи слів, які зазвичай їх оточують. Схожі штуки в комп’ютерній лінгвістиці називаються векторами (див.). Ось як це виглядає:
- легалізація => узаконення, коли поряд є слова “зброя”, “вогнепальний”, “наркотики”, “марихуана”, “проституція”…
- легалізація => відмивання, коли поряд є слова “гроші”, “кошти”, “майно”, “незаконний”, “отриманий”, “шляхом”…
- легалізація => підтвердження, коли поряд є слова “документ”, “консул”, “консульський”, “апостиль”…
Цей підхід зрозумілий і для людини, і для комп’ютера. Для комп’ютера я став робити це так: беремо і відраховуємо 5 слів ліворуч і 5 слів праворуч від знайденого слова “легалізація” в тексті (далі по тексту — “відстань 5”), і перевіряємо, скільки з них входять у ці списки. Чому 5? Так порадила робити Мар’яна Романишин на чудовій лекції з комп’ютерної лінгвістики. Щоправда, це стосувалося здебільшого англійської мови, де інші принципи розташування слів у реченні і взагалі все трошки інакше. Але я вирішив все ж поки спинитися на числі 5. Пізніше я збільшу його. Отже, має “вигравати” група з більшою кількістю наявних слів. Однак деякі нестандартні приклади одразу показали, що такий підхід досить обмежений і непродуктивний. Наприклад:
Консули вважають легалізацію проституції, як і документів, що пояснюють походження коштів відповідних закладів, абсурдом.
Тут здоровий глузд каже нам (окрім того, що речення якесь абсурдне), що мається на увазі (1)узаконення [проституції], але за нашим арифметичним принципом “виграє” (3)підтвердження, бо:
(1)узаконення => 1 (проституція)
(2)відмивання => 0 (бо слово “коштів” стоїть надто далеко)
(3)підтвердження => 2 (консули, документів)

Можете зробити алгоритм розумнішим — робіть
Такий наш алгоритм має, як інколи кажуть програмісти, “обмежену область видимості”: він керується лише уявленням про кількість конкретних слів на “відстані 5”. І все. Цього замало. Тому наступний крок — розширити алгоритм, додавши у нього перевірку слова, яке стоїть безпосередньо поруч зі словом “легалізація”. Найчастіше це — іменник у родовому відмінку (в англійській мові це іменник після слова “of“), що є найсильнішим індикатором того, який сенс має наше багатозначне слово.
Переконайтеся самі: “легалізація марихуани”, “легалізація документа”, “легалізація коштів”. Інколи, звісно, це слово може бути відділеним (діє-)прикметником: “легалізація гладкоствольної зброї”, “легалізація підписаного документа”, “легалізація зароблених коштів”. Тому, окрім “відстані 5”, в нас буде ще “відстань 1”, яка буде мати пріоритет.

Слово на “відстані 1” повинне домінувати!
І тут я задався питанням, як математично розставляти пріоритети для алгоритму в оцінці всіх цих контекстів. Чи переважає одне найближче слово за силою два-три більш віддалених слова? А якщо їх чотири-п’ять? В який момент алгоритм має піддати сумніву це найближче слово? Які коефіцієнти виставити? Тут виникає більше питань, ніж відповідей. Що б ви зробили на моєму місці?
Тому прийшов час втілити свою давню потаємну мрію — зробити для цього нейронну мережу. Бо нейронні мережі якраз спеціалізуються на перетворенні різношерстих вхідних даних у конкретні висновки/відповіді, причому за своїм “внутрішнім переконанням”, виробленим на особистому досвіді. Механізм їх роботи запозичений з біології, в цьому їх суть. Вони вміють “розпізнавати” зображення, звуки, приймати рішення про видачу людині кредиту та робити інші непрості речі.
Їх світ — неймовірно захоплюючий!
Не заринаючись особливо в теорію нейронних мереж і не витрачаючи кілька років на їх вивчення (разом з предметом, історією і актуальністю), вирішив для початку створити невелику мережу, яка б мінімально виконувала поставлену задачу. Я переписав код з одного посібника, трохи змінив схему і отримав таку структуру:
- шість вхідних нейронів, для позначення кількості співпадаючих слів для кожного з трьох сенсів на “відстані 5” і на “відстані 1”;
- три “приховані” нейрони (бо так порадив посібник, але мені пізніше доведеться зробити по-своєму);
- три вихідні нейрони, які працюють за принципом “переможець отримає все”, тобто той з них, що отримає найбільший сигнал, і буде давати відповідь за всю мережу.
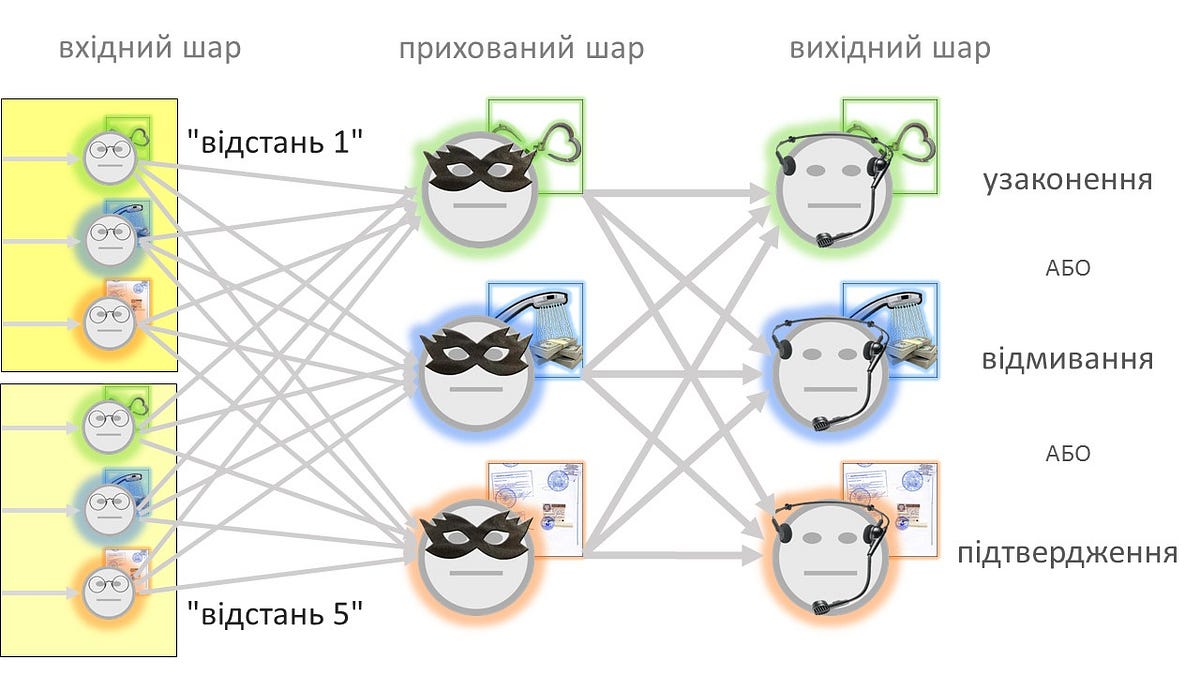
Так, нейрони можуть (і повинні) грати свої ролі
Суть роботи цього чуда максимально коротко:
- Алгоритм каже нейронній мережі, скільки у запропонованому реченні є слів з групи кожного сенсу на “відстані 5” і “на відстані 1”.
- Вхідні нейрони сприймають ці сигнали, передають їх на приховані нейрони, відбуваються внутрішні операції зміщення, активації, підсумовування тощо (детальніше про них можу розказати окрему історію, якщо захочете).
- Далі відбувається те ж саме, але вже між прихованими і вихідними нейронами.
- В результаті має відбутися одна з таких подій:
- активується один з трьох вихідних нейронів (тобто мережа обере найбільш ймовірний сенс);
- не активується жоден (якщо контекст не дозволяє виявити сенс);
- активується кілька нейронів (що, по суті, не повинно траплятися, але трапляється, і це означає, що мережа налаштована неправильно або взагалі має дефектну логіку роботи).
Але перед тим, як запускати нейронну мережу, треба ще виставити спеціальні “ваги” для всіх міжнейронних зв’язків. Вирішив поставити умовні числа, за якими значення на “відстані 1” цінуються в 4 рази вище, ніж значення на “відстані 5”. Почав тестити. І воно запрацювало!
Але далі я помітив, що інколи трапляються кумедні випадки: мережа для деяких сумнівних речень видає одразу кілька відповідей, тобто заявляє, що слово “легалізація” має одразу два сенси. В принципі, це можна обробити програмно, але хотілося зробити розумну мережу, яка зможе потім навчатися на тестових вибірках за допомогою алгоритму “зворотного поширення помилки”.
Тому я почав розбирати логіку роботи цієї нейромережі на всіх рівнях і зрозумів, що з математикою там не все так просто, і її треба переробляти. Якщо ви ще не втомилися читати, то зараз дізнаєтесь, як була зроблена наступна, досконаліша модель нейромережі, посилена “нейронами сумніву”, “нейронами заборони”, “алгоритмом інтерпретації” та іншими штуками.

Щоб зробити комп’ютерну програму “мислячою”, необхідно глибше зануритись у власне мислення, а це не завжди приємний досвід.
Одна з вразливостей першої нейромережі – нездатність проявляти базову когнітивну здатність людини — здатність сумніватися. Також у ній були інші принципові недоліки, які більш-менш вдалося усунути. Оглянемо 5 нововведень, які зробили цю нейромережу ефективнішою.
Але перед тим, як ми вирушимо далі, маю дещо уточнити. За весь процес розпізнання сенсу слова відповідає не лише одна нейромережа. Ось схема всього наколупаного мною програмного забезпечення:
- веб-інтерфейс, з якого тестувальниками відправляється чергове підступне речення і на яке повертаються результати його оцінки (далі — “Веб–інтерфейс”);
- підготовча частина, де за допомогою контекстних словників та різноманітних досягнень мов програмування досліджується це речення, в результаті чого формуються сигнали для вхідного шару нейромережі (далі — “Підготовчий алгоритм”);
- власне нейронна мережа, яка завдяки послідовності математичних операцій формує сигнали на своєму вихідному шарі (далі — “Нейромережа”);
- алгоритм інтерпретації, який оброблює фінальні сигнали Нейромережі та видає на їх базі вердикт автору підступного речення (далі — “Алгоритм інтерпретації”).

У біології нейромережі теж не самі по собі: у них є свої постачальники даних
Нововведення 1 — вміння розбірливої далекоглядності
Після запуску першої версії швидко стало зрозуміло, що “відстань” у 5 контекстних слів від багатозначного слова для української мови явно замала. Ось чудовий приклад від одного з тестувальників:
“… однак документи, які б підтверджували раціональність нашої ідеї, не пройшли легалізацію.”.
В цьому випадку єдине корисне для наших цілей слово “документи” стоїть на позиції -9 (тобто дев’яте слово зліва). Тому я вирішив збільшити цю відстань до 10. Звісно, інколи потрібні контекстні слова зустрічаються і на більшій відстані, але я вже вирішив, що “наше дослідження має суто дослідницький характер” і тому не потребує такої точності. Також вирішив перевірку на контекстні слова проводити з 2-ї позиції, а не з 1-ї, щоб ця група з трьох нейронів відповідала лише за своє поле видимості, і не залазила на чужі поля, які знаходяться на “відстані 1”. Тому цю групу нейронів я умовно назвав “Both2to10”, а самі ці нейрони далі буду називати “Both2to10-нейрони”.
Однак це ще не все. Раніше знайдені слова з кожного з трьох контекстних списків просто рахувалися і на відповідні вхідні нейроні подавалася їх арифметична сума. Але тут мене охопив сумнів, адже взагалі на практиці виходить так, що чим ближче контекстне слово до багатозначного слова, тим більшу статистичну вагу воно має в процесі визначення його сенсу. Тому число в сигналі кожного Both2to10-нейрона має відображати не просто арифметичну суму знайдених слів, а ще й віддаленість кожного з них. Через це я вирішив зробити алгоритм більш природнім: щоб вага контекстного слова залежала ще й від його конкретної фактичної відстані, а не лише від факту входження в умовний діапазон “відстань 2-10”. Що менша ця відстань, тим більший вплив. Сума впливів знайдених слів по кожній контекстній групі множиться на спеціальний коефіцієнт, і це стає сигналом для відповідних Both2to10-нейронів.

Думаю, що квадрат величини збільшення контекстної відстані прямо пропорційний кількості знайденого на цій відстані сенсу
Нововведення 2 — вміння визначати пріоритети
Раніше найбільший пріоритет для Нейромережі мали слова, які просто знаходилися на “відстані 1” навколо багатозначного слова. Однак це дуже грубий підхід для нашої мови. З позицій синтаксису і семантики для визначення сенсу багатозначного іменника “легалізація” найбільшу вагу має іменник, який йде після цього слова в родовому відмінку (в англійській мові це іменник після слова “of“) і не відокремлений від нього розділовими знаками. Тобто ці два слова знаходяться у відношенні підрядності: слово “легалізація” не має сенсу саме по собі, щось/хтось має підлягати цій легалізації. Це безумовний показник. Як би ви не будували речення, насичаючи його протилежними сенсами, якщо це відношення підрядності присутнє, то воно буде мати пріоритет у будь-якому хаосі. Наприклад:
“Поважні консули з документами і апостилями їхали на ішаках, і легалізація доходів від продажу кулеметів та пістолетів, а також героїну і кокаїну, бентежила їх думки…”
Група нейронів, яка відповідає за цей підрядний зв’язок, називається “AfterHard”. Якщо провести умовну стратифікацію всіх груп вхідних нейронів, то AfterHard-нейрони — еліта вхідного шару нейромережі, їх слово має найбільшу вагу. Причому лише один AfterHard-нейрон з трьох може бути активований одночасно, бо, вочевидь, лише одне слово може стояти першим після багатозначного слова. 🙂 Це багато що спрощує.
Але це ще не все. Інколи це підрядне слово може стояти не після багатозначного слова, а перед ним, тоді як багатозначне слово потрапляє в дієприкметниковий зворот. Ось як це виглядає:
“Розквітає проституція, легалізація якої могла …”
Тут правильний сенс слова “легалізація” буде “узаконення”. Однак чому цей показник не можна прирівнювати за силою до групи “AfterHard”? А тому, що можливі такі хитрі прийоми:
“Розквітаючої проституції, легалізація доходів від якої могла …”
“Розквітаючої проституції, легалізація документів в умовах існування якої має потенціал для …”
Як бачимо, в цих випадках правильний сенс слів “легалізація” буде не “узаконення”. Тому алгоритмічно не можна ототожнювати “слово перед” та “слово після”. От і з’являється у нас наступна група нейронів — група “BeforeSoft”. Чому “Soft”, а не “Hard”? Тому що контекстний словник для цієї групи містить різні морфеми, корені слів тощо.
Поряд з групами “AfterHard” і “BeforeSoft”, є ще група нейронів “AfterSoft”. Сигнал цих нейронів теж базується на слові, яке йде одразу після слова “легалізація”, однак щодо точності пошуку діє такий самий підхід, як і у “BeforeSoft”.
Таким чином, маємо чотири групи з 3 нейронами в кожній, розташовані за спаданням значимості: “AfterHard”, “BeforeSoft”, “AfterSoft”, “Both2to10”. У кожній групі кожен нейрон має свій вплив на відповідний йому нейрон прихованого шару мережі. Вже в нас є 12 вхідних нейронів, що у два рази перевищує їх кількість у попередній нейромережі. Але цього все ще замало.

У нейромережі стратифікація може бути в межах одного шару (в моєму випадку — вхідного). Але немає єдиного “правителя”. Рішення колегіальні. Щоправда, баланс сил може бути нерівний
Нововведення 3 — вміння сумніватися
Сумнів — це наш природний стан. Він виникає, коли щось йде не так, коли нема ясності. Носити краватку чи не носити? Давати хабар чи не давати? Коли алгоритм бачитиме кілька контекстних слів, які належать до різних сенсів, то він має “засумніватися”. Засумніватися у доцільності однозначного приписування слову “легалізація” одного з цих сенсів. Тобто він має вирішити, що краще промовчати, аніж спробувати вгадати і помилитися. Так іноді вчиняємо і ми. Тому вирішив увести на прихований і вихідний шари мережі “нейрони сумніву”.
Початково схема роботи нейронів сумніву була така:
- нейрон сумніву на прихованому шарі має “побачити”, що на вхідному шарі є якась підозріла активність у різних смислових групах (наприклад, з групи “BeforeSoft” лунає, що має бути сенс “узаконення”, а група “AfterSoft” кричить, що сенс “відмивання”, і до неї ще долучається група “Both2to10”);
- цей нейрон активується, якщо розрахований сигнал на базі сигналів різних нейронів тих груп перевищує пороговий (0,5);
- він має пригнічити вихідні нейрони, які відповідають за констатацію наявності сенсів, та активувати на повну вихідний нейрон сумніву.
- сигнал вихідного нейрона сумніву передається в Алгоритм інтерпретації, що і визначає долю майбутньої відповіді.
Так спершу я собі придумав. Але виявилось, що проста математична модель Нейромережі за такою схемою працює парадоксально: коли в одній смисловій групі буде дуже сильний сигнал, а по інших групах буде нульовий, наприклад у реченні “Збройний уряд веде наркотичну легалізацію наркотиків, кокаїну, пістолетів, проституції, кулеметів і творів Гітлера”, то нейрон сумніву спрацює! Бо сигнал для сенсу “узаконення” буде дуже сильний. Зменшення “чутливості” нейрона сумніву — поганий хід, тому що він перестане “помічати” ті ситуації, коли “сумнів” вже потрібний. До того ж, з математичної точки зору ця проблема все одно залишиться. Тому мені довелося створити нейрон сумніву ще й на вхідному шарі, і його сигнал розраховувати за допомогою окремого шматочку коду, який і увійшов до Підготовчого алгоритму.
Тепер алгоритм буде розумно стверджувати, що сумнівається, досліджуючи речення на кшталт таких:
- “Хіба може легалізація одночасно означати узаконення, відмивання та підтвердження?”
- “Консульська легалізація трансплантації документів ще заявить про себе.” (в цьому випадку алгоритм ще додасть, що він обрав би сенс “підтвердження”)

Сумнів може утримати від невдалого рішення. Наприклад, від розказування несмішного анекдоту
Нововведення 4 — вміння відмовлятися
Інколи слово “легалізація” вживають некоректно. Наприклад: “легалізація трудових відносин”, “легалізація заробітної плати”, “легалізація програмного забезпечення”. Під словом “легалізація” в таких випадках розуміється щось на кшталт “переведення чогось в режим законного використання”, “перехід на законні основи використання/здійснення чогось”. Але це, з юридичної точки зору, неправильний вжиток цього слова, тому я вирішив, що алгоритм в таких випадках повинен принципово відмовлятися працювати далі з таким реченням.
Для цього я створив “нейрон заборони” на всіх шарах Нейромережі. Той з них, який вхідний, активується Підготовчим алгоритмом при виявленні названих вище та деяких інших конструкцій у зв’язці з нашим багатостраждальним багатозначним словом. Логіка його робота проста, як камінь. Якщо цей нейрон активувався, він безжалісно пригнічує всі інші нейрони і безжалісно активує нейрон заборони на прихованому шарі. Таким чином, вердиктом як Нейромережі, так і всього алгоритму, незалежно від загального балансу сил, буде відмова виявляти сенс у таких умовах.

Із забороною все просто: просто не роби
Нововведення 5 — вміння додатково інтерпретувати
Приклад минулої Нейромережі змусив мене підозрювати, що, напевно, нема нічого поганого в тому, щоб з вихідних сигналів Нейромережі не напряму робити якісь висновки, а додатково обробляти їх перед винесенням остаточного рішення. Так і з’явився Алгоритм інтерпретації. Це дозволяє, наприклад, не просто констатувати сумнів, але й показати, якому сенсу Нейромережа надала би перевагу, якби не цей сумнів. Але це, щоправда, вже не входить до роботи самої Нейромережі. Це вже робота таких штук, як “if/else” і математичне порівняння, який сигнал більший за інші два. На цьому перелік нововведень слід завершити.

Просте зважування отриманих результатів може бути вельми дієвим
Підсумки
- Попередня схема нейронних зв’язків “6-3-3” змінилася на “14-5-5”, що дало значно більші можливості і більшу схожість роботи цього алгоритму до людського мислення. Однак все ж я ні в якому разі не перебільшую його можливості. Наразі ще є як мінімум дві вразливості цієї Нейромережі, які я хотів би, щоб ви розгадали. 🙂
- У першої нейромережі разом з веб-інтерфейсом було 4 варіації вердикту (“сенс 1”, “сенс 2”, “сенс 3”, “слабкі сигнали”), а в нової їх стало набагато більше: 3 (3 можливі сенси)+ 4 (“слабкі сигнали” + 3 можливі “симпатії”)+ 4 (“сумніви” + 3 можливі “симпатії”)+ 1 (“відмова”) = 12.
- Ускладнення часто варте результату, однак у більш складної системи з’являється більше вразливостей (це твердження справедливе і в біології). Тому майже експоненційно зростає кількість коду, який треба писати, щоб обробляти вразливості і баги складнішої системи.
Прошу тестити це чудо ось тут і чекаю на ваші коментарі. 🙂
Схожі статті
 ICO просить вас сплатити data protection registration fee?
ICO просить вас сплатити data protection registration fee?
26 Березня, 2024 1 хв
 Експорт оборонних технологій – основні правила комплаєнсу для міжнародної співпраці в MilTech
Експорт оборонних технологій – основні правила комплаєнсу для міжнародної співпраці в MilTech
7 Травня, 2026 1 хв
 Суб’єкт даних подав запит про видалення даних – що робити?
Суб’єкт даних подав запит про видалення даних – що робити?
9 Лютого, 2026 1 хв

 Виробництво для Сил оборони: що має знати виробник, як бізнес
Виробництво для Сил оборони: що має знати виробник, як бізнес
15 Листопада, 2025 1 хв



